Welcome to part 2 of my tutorial to create a RCP application. If you followed the first part of the tutorial, your workspace will contain this project.
If you didn't, then download the file and use "Import ..." from the File menu. Select "Existing Projects into Workspace" from the folder General.
Choose "Select archive file:" and enter the path to the downloaded file. Eclipse should now offer the project "WriterTool" in the big area in the middle. Click Finish to import it into your workspace.
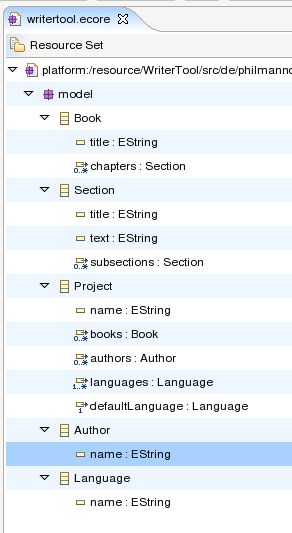
First, we'll need a new Chapter EClass. Create one as a child of "model".
The first version chapter will be pretty simple: Just add one attribute "text", set EType to EString.
The interesting part comes with the recursive nature of the book content.
Also, we should think about setting limits for the chapters in a book.
First, well tell EMF that a book can contain chapters. To do that, select the book and "New Child / EReference" from the context menu.
Unlike an attribute, an EReference allows you to use other model objects as "value". Try it: Create another attribute and try to set the type to Chapter. EMF won't let you.
But with references, you can do just that. So delete the attribute and set the name of the new reference to "chapters". Then, change the EType to Chapter.
Now, a book can contain a chapter.
A single chapter doesn't seem very useful for a book. To be able to add more chapters, you can increase the upper bound of the chapters reference.
But let's think about the implications, first.
Do we want to impose some restrictions? Do we want to allow books without chapters? How about a book with 100 chapters? Or 1000? A million?
EMF allows very exact control here: We could set the lower bound to 1, effectively disallowing books without chapters. While that may make sense from a book reader point of view, it will irritate the application user (the author) later: He cannot create empty books anymore.
So while our guts might feel uneasy with the idea of empty books, the actual user of our program might want to be able to create empty books, for example, to be able to attach ideas to it before he starts on the actual text.
The model, on the other hand, will continue to work with empty books: The chapters are no vital information. Other things could cause problems: A missing or empty title, for example. Imagine the user creates five books and sets no titles. How is he supposed to differentiate between them?
Therefore, since there are no string arguments to set a lower limit and it might be more comfortable for the user later, we won't impose one.
How about the upper limit? A book with five chapters makes sense. 10 is okay, too. 100 ... maybe not. 1000 certainly not. A million? Never!
Are you sure?
Really sure?
Absolutely sure?
Think of a collection of poems. Every poem might go into its own chapter. There can easily be 100 or 1000 poems in a single book.
If you put every article of something like Wikipedia or the Encyclopaedia Britannica into its own chapter, you will quickly break the 100'000 barrier. The Britannica has more than 120'000 articles, at the time of writing (24. March 2006), Wikipedia had 1'040'783 articles. Definitely more than a million.
Lesson: You might think you know but you never know your users and their uses. Unless there is a really compelling reason, try to impose as little limits on your users as possible.
So for the chapters in a book, we come to the conclusion that the best values are 0 for the lower bound (allowing empty books) and -1 for the upper bound (allowing unlimited number of chapters).
After you have changed the properties, you'll notice these things: Many is true and The icon of the property has changed (showing a "0...*"). This gives you a quick indication about the type of reference.
Also, we can easily leave the limits this way because if we want or have to change our mind later, EMF will allow us to make the change in the ecore definition and it will then add (or remove) all the limit checks where necessary. This allows to postpone design decision until you have to make it, but then, you will know why. Right now, we would play the fortunetellers game: Predict the needs of the user in advance. And who believes in fortunetelling?
In our discussion above, we came to the conclusion that an author can exist without his book and, because of the way authors work, a book can exist without chapters but a chapter without a book is probably not very useful.
From the models' point of view, a chapter is closely related to the book. If I move a book from one project to another, save or load it, I want the chapters to tag along. After deleting a book, I certainly don't want to have to manually find all chapters in my project and delete them as well.
If I send a book to another author, the application should include all chapters without me having to tell it.
This kind of relationship between two model objects is called "containment". In EMF lingo, a Book is a container for Chapters.
This means that you can still create chapters without a book and work with them. But when you attach a chapter to a book, they start to behave as a unit: If you save the book to a file, the chapters will be saved, too. If you delete the book, the chapters will be deleted as well. If you copy the book (for authors, this is legal!), you expect the copy to contain all chapters as well. If you delete a chapter from the copy, you certainly don't expect the same chapter in the original to vanish.
These are all details which you need to care about when not using EMF. If you forget one of them, your model will behave strange. Users will loose work or at least time. They will be irritated, file complaints and yell at you.
With EMF, you simply change the Containment property to true.
That's it.
Now, when adding an object of type Chapter to the chapters list of a Book object, the book will take ownership of the chapter and manage it for you.
The list is ordered, too, so the sequence of chapters won't change when you save your work in a file and load it again.
There is just one question left: Why isn't this the default?
Let's go back to the translating of books. In every project, there will be a finite number of languages, like english, german, french, italian. Someone will be responsible for them. Let's assume (we aren't there, yet, so we don't know for sure) that the project will be the container for the languages.
So in the project, we'll have a reference called "languages" with Containment set to true. In the books, there will also be a reference. This time, Containment will be false because the project already manages the languages. If both were true, the books and the project would fight for the ownership of the language.
Every time you would attach a language to an object (maybe languages will be attached to chapters as well? How about a book which is written in two languages like a dictionary?), that object would take ownership of the language. Since only one object can own another at any time (that's an EMF feature or limitation, depending on your goals), EMF would tell the old owner that he no longer owns the language.
So every time you save your project, the language will probably move. Imagine you had an object which was used more seldom. It would move around your project "sometimes", seemingly random. Users would be confused, developers baffled. It would take a long time to find out what is going on and probably even a longer time to fix it because a lot of code might have already been written.
As it is now, you can forget to set the Containment for every object. In this scenario, EMF will notice that no one feels responsible for it when you save your model to a file and raise an Exception.
Instead of a strange, hard to find error, you will always get a very definitive, clear exception which tells you what's wrong.
When working with EMF, you'll find that at several places, the defaults and rules don't seem to make sense or you'll find they get in your way.
What that happens, take a step back and think what you try to achieve. Chances are that you'll find that you just made a mistake and EMF just found it for you.
In a few, rare occasions, it might happen that you stumbled over an actual bug in EMF.
But more often than not, EMF is right.
Let's generate the code for the chapters to see how the containment works. Switch to the genmodel editor and run Generate Model.
Something happens (the progress dialog pops up and goes away). You will now see a couple of new files in the Package Explorer but for me, no code was generated ... What's going on?
Currently, the error handling in the EMF editors and code generators is not very mature. If nothing happens, like now, open the Error Log View (Window menu / Show View / Error log).
1: 2: | java.lang.NullPointerException
at org.eclipse.emf.codegen.ecore.genmodel.impl.GenTypedElementImpl.getTypeGenPackage(GenTypedElementImpl.java:65)
|
This usually means that something is missing in the model. In my case, I forgot to set the EType of the text attribute of Chapter. After setting it to EString, I got the same files that you have.
Containment Code ... sounds more like a rule book for pest control.
Anyway. Here is what EMF generated in the Book.java file.
30: 31: 32: 33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: | /** * Returns the value of the '<em><b>Chapters</b></em>' containment reference list. * The list contents are of type {@link de.philmanndark.writertool.model.Section}. * <!-- begin-user-doc --> * <p> * If the meaning of the '<em>Chapters</em>' reference list isn't clear, * there really should be more of a description here... * </p> * <!-- end-user-doc --> * @return the value of the '<em>Chapters</em>' containment reference list. * @see de.philmanndark.writertool.model.WriterToolPackage#getBook_Chapters() * @model type="de.philmanndark.writertool.model.Section" containment="true" * @generated */ EList getChapters(); |
/WriterTool/src/de.philmanndark.writertool.model/Book.java (Line 30-44)
This time, EMF created a method which returns a list of chapters (which makes sense since there can be more than one and they are ordered). Note that the type of the elements in the list are declared after the @model tag and the containment="true" in line 69.
EMF will make sure that only Chapters appear in this list. You'll get an error if you try to add different objects to it. It doesn't quite as far as using generics in Java 1.5 (we still need casts when we get objects from the list) but it works with Java 1.4 and you can add additional methods which use the Java 1.5 syntax later.
Our first visit is the new getChapters() method.
58: 59: 60: 61: 62: 63: 64: 65: 66: 67: 68: 69: 70: 71: | /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated */ public EList getChapters() { if (chapters == null) { chapters = new EObjectContainmentEList(Section.class, this, WriterToolPackage.BOOK__CHAPTERS); } return chapters; } |
/WriterTool/src/de.philmanndark.writertool.model.impl/BookImpl.java (Line 58-71)
Notice that EMF only creates the EList when you ask for it. This is one of the design basics of EMF: Try to be as lean and fast as hand-written code (or better). It will not create unecessary objects unless it has to. So even for very large models, the memory footprint should be almost as low as if you had written and optimized the code.
If you look at toString(), you'll see that the chapters won't be included by default. This also makes sense when you think about the Wikipedia example: You don't want an innocent System.out.println() to blow up all available memory. Since EMF cannot tell how many objects there will be, it is conservative.
That probably makes you wonder what happens when EMF knows. One nice thing of code generation is that you can experiment. Just set the Upper Bound of Book.chapters to 1 and regenerate. No need to worry that you might forget a place when you take this change back.
As expected, the code in Book.java was changed to use a getter and setter (no need for a list for a single child) but toString() didn't change. So EMF is very conservative. Maybe more than we'd like at this place but after Eclipse crashed the first time after you clicked on an item in the Variable view because toString() ate all your free RAM, you'll be grateful.
Also note the warning about the unused import in Book.java. EMF only adds new imports. Maybe a later version will actually call organize imports.
Remember that we wanted to be able to add sections to chapters and subsections to sections? We'll do that now.
The point of these children is to be able to structure the contents of a book better. But from the view-point of the model, they look alike: Each has a parent and contains some text. They are even used in the same way. It's only that we are used to refer to the different parts of a book with different names.
So it probably doesn't make sense to create more classes to implement sections and subsections but to reuse the existing chapter class.
Do you also have this uncomfortable feeling? Putting a chapter into another chapter to simulate a section. Or using a chapter as a child of a section (which really is another chapter which is only a section because it's a child of a chapter which is a child of a book).
If you feel as confused as I, then that means something is fishy here and we should sit back and think about it.
When Einstein was asked why he was so sure that his famous formula E = mc2 was correct, he answered: It felt right.
Most people believe that software development is part of the mathematics department (computers compute, right? No room for feelings or doubts!)
To understand why this is wrong, let's look at a simple example:
You're a secretary working for a big company in a huge, 20 story building. It has 6 elevators. You boss asks you to put an announcement into the evelators because someone is always parking in his space (Hey, it's just an example, ok?).
So you roll your eyes (at his back), start your favorite Word-processor and print six announcements.
Roughly one hour later (depending on the mood of your Word-processor, the network, your computer, sunshine, coffe-availability, your weight and the average distance to the rest/break/feng-shui/joga room and the amount of great ideas of your boss per hour), you arrive in front of the elevetors.
You call one of them (let's call him A), tape the announcement to the back wall and leave it.
Now, you press the call button again.
Unfortunately, someone really clever was there before you and created an intelligent elevator: A is still there, has no ride and maybe even his doors open.
So the other elevators will ignore you.
It takes you a few seconds to realize this. Then, you start to think about the solution. In software development, we call this the design step: You have a problem (how to get into the other five elevators) and now, you're looking for solutions.
The most simple one is to step into elevator A (he's still waiting for you to make up your mind) and select another level. Preferable the one with the greatest distance to this one.
This is the moment when your design decision meets reality. Everybody knows that stupidity is infinite, so the question is: How clever is the little computer hidden somewhere in the building that controls the cabins?
It usually knows if the level selection comes from within a cabin or from the button in the wall of a floor (if it didn't, then pressing level five inside elevator A could send elevator B for the trip).
He's also watching the weight of the cabins (100% of all elevator customers prefer controlled rides without sudden drops because of overweight).
Was some software developer so clever as to make the controlling computer realize this situation: Someone presses the button inside and then leaves before the doors close?
It's a well known fact that software developers hate children (that they wipe the harddisk to install SuperGame Xyz has nothing to do with it!). So maybe the genius which made sure that the elevators learn to gather near the lower levels in the morning (because most people want to go up) and at the higher levels in the evening (because people want to leave) told the little computer: If someone selects a level inside the cabin and the weigth sensor tells you nobody is inside, that's just kids playing with the controls, so ignore it.
The computer doesn't understand anything about kids but he knows everything about ignoring someone.
So we have a secretary which is carefully boiled to ignition point because someone (who isn't there and doesn't even know about it) was very clever.
You could ask five friends to help you out but you have the feeling that they will laugh their guts out before you can finish the second sentence (which contains the explanation why you are not stupid).
You could use the stairs but chances are that A is still the closest elevator if you move less than five levels and you don't get payed enough for that kind of exercise. If A was still the closest one, the elevator control would send it happily after you in the blissful knowledge of a job done right.
While the movement of elevators can be expressed with a couple of simple physical formulas, the behavior of it cannot. An elevator is just a complicated piece of machinery but even though it's controlled by a computer doesn't mean it will behave in a predictable way.
That's the dilemma with software development: It's not at all about computing things but about connecting the abstract world of mathematics to reality. To give you an idea about how hard that usually is, just remember your days at school. And the math teacher had two advantages: He could see you while he tried to connect to you and he was a human.
In software development, we try to create something for someone we'll never see. And when we're finished, our creation has to be able to handle this someone alone. It's much more like throwing a five-year-old out of your house (hey, he can walk and talk!), knowing he'll have to attend a dinner with The Queen of England in three weeks. As the host.
Therefore, forget about all this talk that software development is predictable and just another form of mathematic.
When you look at some code and you feel uneasy, there is something wrong.
Trust yourself.
The problem at hand is that we try to map three real world objects (chapter, section, subsection) to one model object. The cause of the trouble is the meaning of the word "chapter". The sentence "The chapter about scaling is in the chapter about fishing" just makes no sense to us because chapters can't be inside of chapters.
There are two solutions: We can tell everyone who gets in contact that the chapters in our model are also sections or we can use a different term which is more correct.
Section or part come to mind. None of them is really perfect. A part of a book is usually at a high level (table of contents, index, chapters and sections are parts). But most people would be comfortable with the idea to call the different logical parts of the contents of a book "section".
The key point for a good model is to stay close to the real world. If you use "Book" as the name of one of your classes, people will expect it to have the same properties as real books: A title, some text in it, maybe the year of publishing.
If you feel that some part of your model has the wrong name, then change it. EMF will do the rest (well, part of it, as we'll see).
Models are rarely perfect when you create them for the first time. Changes like this one are common and ideally, the development environment should help to do them instead of forcing you to live with every design error you make. If errors can't be fixed, people will start to live in fear and fear never helped.
So after finding that Chapter was a bad choice for the name for the object which contains the sections of your book, we'll rename it to Section. Just click on it and change the name in the Properties View.
The result will be good and bad. There is a reason why the Sample Ecore Model Editor is called "sample"...
When you click on Book.chapters, you'll see that EType of the reference has changed to Section. That's nice. But in the tree, you'll see "chapters: Chapter". That's bad but only a visual glitch. Probably, the tree item caches the label.
To fix this, just change the name of Book.chapters to "chapter" and back to "chapters". Now, the tree will look as expected.
Save and generate. Notice that the genmodel tree is already correct. Nice.
But now, something bad happens. Not really bad, but ... well ...
As you can see, EMF didn't delete the old java files for Chapter (Chapter.java and ChapterImpl.java). This is an unfortunaty side effect of the separation into ecore model and genmodel. The ecore model, like any other EMF model, notices when something is deleted or renamed. The genmodel, on the other hand, is somewhat remote. It just sees all changes but it cannot know if we just deleted Chapter and created Section or if we renamed it. Therefore, it cannot delete the java files.
Even if it knew what happened in the ecore model, it couldn't just delete the files: There could be manual changes in them. Or maybe you renamed Chapter into section and then completely replaced Chapter.java with something else. In this case, you would probably be very upset if genmodel would throw your file away.
Lesson: If you delete and/or rename packages and classes, you have to delete the Java files for them yourself. To make things easier, you should either delete them the moment you change the ecore model (so they are no longer there when genmodel updates the files) or you should put your model files into one package so you can simply delete all files without bothering. We'll see later how to do that.
For now, we'll just delete Chapter.java and ChapterImpl.java manually.
Huh? Errors in BookImpl.java and WriterToolPackageImpl.java? Oh, it's just an import of the Chapter. A quick organize imports fixes this.
To allow to add sections as children of sections, switch to the ecore editor and copy the reference from Book to section and rename the duplicate to "subsections".
Note that we didn't rename "chapters" in Book. The sections which are direct children of a book object are chapters. We just use the same class for them as for subsections. This way, someone who uses the model will see that a book contains chapters (you have to use getChapters() to get them) and that they are implemented with the Section class.
Save and generate.
Books have titles, no names, so we change that and generate. Now, the model looks as we want it.
Time for our first test.
I'm a hughe fan of Test Driven Development. If you aren't, yet, give it a try. Chances are that you'll be much more productive and more happy at work.
EMF somewhat gets in the way of this approach (write the test, then implement the functionality) because there is not much to test as long as there is no model. But there is no need to test the code generation step plus EMF doesn't get in your way writing tests (EMF objects behave like POJOs), so that's not a big loss.
I organize my tests in an extra folder called "test". The tests for a class are in the same package as the class to be tested and the name of the test is the same as the class with "Test" appended.
So my book tests go into test/de.philmanndark.writertool.model.BookTest
Since we are an Eclipse plugin, adding JUnit to the classpath is very simple:
If you open the folder "Plug-in Dependencies" in the project, you'll see that the JUnit plugin was added. Eclipse will now automatically manage this entry for us. This means that you don't have to have Eclipse installed in the same spot as I do, I don't have to include the junit.jar with my project and there will be no problems with the classpath.
Cool.
Go back to BookTest.java. Since JUnit is now in the classpath, we can derive the class from TestCase. Your code should now look like this:
1: 2: 3: 4: 5: 6: 7: 8: | package de.philmanndark.writertool.model; import junit.framework.TestCase; public class BookTest extends TestCase { } |
/WriterTool/test/de.philmanndark.writertool.model/BookTest.java (Line 1-8)
For our first test, we'll create a book with two chapters and one section. Here is the code:
7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: | /** * Create a book with two chapters and one section. * * @throws Exception */ public void testCreate () throws Exception { // Use the factory to create a book Book book = WriterToolFactory.eINSTANCE.createBook(); // Create a chapter and add it to the book Section chapter1 = WriterToolFactory.eINSTANCE.createSection(); book.getChapters().add (chapter1); // Create a section and add it to the first chapter Section section = WriterToolFactory.eINSTANCE.createSection(); chapter1.getSubsections().add (section); // And another chapter Section chapter2 = WriterToolFactory.eINSTANCE.createSection(); book.getChapters().add (chapter2); // Next, we'll add some text content chapter1.setText("This is chapter1."); section.setText("This is the section which is a child of chapter1."); chapter2.setText("The second chapter."); } |
/WriterTool/test/de.philmanndark.writertool.model/BookTest.java (Line 7-33)
We'll use the JUnit Test framework of eclipse to run the tests: Select the Menu Run / Run As / JUnit Test.
Since the file BookTest is active, Eclipse will use it as the test case. Of course the test is a little bit boring but it shows that the EMF model works just like any other POJO.
We'll add some code to see how EMF works:
34: 35: 36: 37: 38: 39: 40: 41: 42: 43: | // Check some relations assertTrue("Chapter 1 is not contained in the book", book.getChapters().contains(chapter1)); assertTrue("Chapter 2 is not contained in the book", book.getChapters().contains(chapter2)); assertTrue("The section is contained in the book", book.getChapters().contains(section)); assertTrue("The section is not contained in chapter 1", chapter1.getSubsections().contains(section)); assertTrue("Chapter 2 contains sections", chapter2.getSubsections().isEmpty()); assertEquals("The number of chapters in the book is wrong", 2, book.getChapters().size()); assertNotNull("There is no text in chapter 1", chapter1.getText()); assertNotNull("There is no text in the section", section.getText()); assertNotNull("There is no text in chapter 2", chapter2.getText()); |
/WriterTool/test/de.philmanndark.writertool.model/BookTest.java (Line 34-43)
Let's run the tests. Huh? Errors?
That's the nice thing about TDD: You might believe that something works in some way but the tests work with facts, not beliefs.
Looking at the code, I have no idea why the section is suddenly in the list of chapters of the book. I'll comment out this test to see what else fails.
Now, I get a green bar and I'm confused. If there are only two items in the list of chapters (see the test in line 40), how can the section be in the list if chapter1 and 2 already are in the list (see line 35 and 36).
That makes me wonder whether the method "contains()" might be recursive.
To make sure that the lists contain only the expected elements (seeing is believing), I'll print them to the console.
45: 46: 47: | System.out.println(book.getChapters()); System.out.println(chapter1.getSubsections()); System.out.println(chapter2.getSubsections()); |
/WriterTool/test/de.philmanndark.writertool.model/BookTest.java (Line 45-47)
The result is:
1: 2: 3: | [de.philmanndark.writertool.model.impl.SectionImpl@2c84d9 (text: This is chapter1.), de.philmanndark.writertool.model.impl.SectionImpl@c5c3ac (text: The second chapter.)] [de.philmanndark.writertool.model.impl.SectionImpl@1b16e52 (text: This is the section which is a child of chapter1.)] [] |
The text attributes show that the expected items are in the respective lists, so why does the chapters list in book contain the sections? This asks for the debugger. I add a couple of lines to help me get on track:
36: 37: | EList list = book.getChapters(); boolean b = list.contains(section); |
/WriterTool/test/de.philmanndark.writertool.model/BookTest.java (Line 36-37)
This code allows me to step directly into contains code without any detours though other code. I set the breakpoint in line 37 and start the debugger.
Eclipse asks whether it should switch to the Debug perspective. Yep and I also tell it to remember this choice. Debug debug debug.
Strange ... contains() returns false! Oops, the test itself is wrong! I should check for false instead of true. Ahem. A quick fix and I'm green.
37: | assertFalse("The section is contained in the book", book.getChapters().contains(section)); |
/WriterTool/test/de.philmanndark.writertool.model/BookTest.java
Back to completing the model.
Like books, chapters and sections have titles, so we add that (just copy the attribute from the Book to the Section). The new title attribute is at the end of the list but the editor supports drag'n'drop to sort the items. Let's more the title to the top.
After saving, generation, I add a few more tests. Now the test looks like this:
7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: 45: 46: 47: 48: 49: 50: | /** * Create a book with two chapters and one section. * * @throws Exception */ public void testCreate () throws Exception { // Use the factory to create a book Book book = WriterToolFactory.eINSTANCE.createBook(); // Create a chapter and add it to the book Section chapter1 = WriterToolFactory.eINSTANCE.createSection(); book.getChapters().add (chapter1); // Create a section and add it to the first chapter Section section = WriterToolFactory.eINSTANCE.createSection(); chapter1.getSubsections().add (section); // And another chapter Section chapter2 = WriterToolFactory.eINSTANCE.createSection(); book.getChapters().add (chapter2); // Next, we'll add some text content chapter1.setTitle("Introduction"); chapter1.setText("This is chapter1."); section.setTitle("Section title"); section.setText("This is the section which is a child of chapter 1."); chapter2.setTitle("Bla Bla"); chapter2.setText("The second chapter."); // Check some relations assertTrue("Chapter 1 is not contained in the book", book.getChapters().contains(chapter1)); assertTrue("Chapter 2 is not contained in the book", book.getChapters().contains(chapter2)); assertFalse("The section is contained in the book", book.getChapters().contains(section)); assertTrue("The section is not contained in chapter 1", chapter1.getSubsections().contains(section)); assertTrue("Chapter 2 contains sections", chapter2.getSubsections().isEmpty()); assertEquals("The number of chapters in the book is wrong", 2, book.getChapters().size()); assertEquals("Title of chapter 1 is wrong", "Introduction", chapter1.getTitle()); assertEquals("Text of chapter 1 is wrong", "This is chapter1.", chapter1.getText()); assertEquals("Title of the section is wrong", "Section title", section.getTitle()); assertEquals("Text of the section is wrong", "This is the section which is a child of chapter 1.", section.getText()); assertEquals("Title of chapter 2 is wrong", "Bla Bla", chapter2.getTitle()); assertEquals("Text of chapter 2 is wrong", "The second chapter.", chapter2.getText()); } |
/WriterTool/test/de.philmanndark.writertool.model/BookTest.java (Line 7-50)
Note that I changed the checks to verify the actual contents of the fields instead of just checking against non-null. This way, I'll see when things get mixed up.
This pretty much completes this part of the model because I have no idea what else I could add to books and sections at this time.
If you didn't follow me so, far, you can download the current state of the project.
In our model, we would like to be able to have several books. To get there, we need a structure which contains (manages) the books for us. Let's create a Project class with a list of books as children.
You might wonder why I added this last sentence. The reason is that the download has bug here.
Why didn't I fix it?
The world is never perfect. When working with EMF, it's easy to forget that a lot of things are going on in the background. Things like wrong properties are easy to miss and the resulting behavior sometimes doesn't point directly at the source of the problem. And a little change in the properties can have a very large impact in how the model behaves.
Therefore, get used to the idea to check twice.
At least, until EMF adds a new icon in the editor which shows containment more prominently :-)
With our knowledge, it's simple to add two more objects to the package. We want to be able to add authors (for example, for copyright statements) and the language in which each book is written in.
Every project will use a default language. If there wasn't one, the author would have to specify one every time he added a book, section, whatever.
So add another reference to Project:
The containment has to be false, since the languages are already managed by the Project.languages list. We are only selecting an item from this list here (think of a combo box: Selecting an item doesn't remove it from the list of selections).
And we ask that every project has a default language (Lower Bound). If there is none, the project is not complete. Later, when we add a UI, we'll always supply English, so the user doesn't have to worry (but he can if she so chooses).
Since we insist that there must be a default language, that also means that the list of languages can never be empty as well. So set the Lower Bound there to 1 as well.
Completely expand the model tree. See that everything has a name or title?
Also, do you remember when we said that an author might want to be able to see where he worked last? So each section and each book needs a timestamp. This timestamp should get updated when we change something.
If we were using plain Java, we'd just move the name to a base class and inherit everything from it.
With the timestamp, we would do the same and then add code to update it every time a setter is called.
Of course, sometimes, the latter (the call to updateTimeStamp()) would get lost but over time, all these bugs would be found and fixed.
Sounds like fun, eh?
Let's see if there is a better way. Select the class Language.
In the Properties View, you'll see "ESuper Types". Types? Plural?
Unlike Java, EMF allows to inherit from several classes at once. How does it work?
Just like it would work with Java: EMF generates a lot of interfaces for you and then a class which implements all of them. Since EMF also generates the code to implement all the interfaces, you can do something really cool: Build classes from building blocks.
Right now, we'd like a building block which gives an object a name. This is such a common problem, that EMF already offers a solution out of the box: ENamedElement:
If you open Language.java, you'll see nothing surprising:
22: 23: 24: | public interface Language extends EObject, ENamedElement { } |
/WriterTool/src/de.philmanndark.writertool.model/Language.java (Line 22-24)
The implementation is much more interesting:
25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: 45: 46: 47: | public class LanguageImpl extends ENamedElementImpl implements Language { /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated */ protected LanguageImpl() { super(); } /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated */ protected EClass eStaticClass() { return WriterToolPackage.Literals.LANGUAGE; } } //LanguageImpl |
/WriterTool/src/de.philmanndark.writertool.model.impl/LanguageImpl.java (Line 25-47)
Now that's short (especially when compared to AuthorImpl.java).
But does it work as expected? Time to test.
Isn't ambiguity funny?
Create a new class ProjectTest in test/de.philmanndark.writertool.model:
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: | package de.philmanndark.writertool.model; import junit.framework.TestCase; public class ProjectTest extends TestCase { /** * Create a project with two languages * * @throws Exception */ public void testLanguage () throws Exception { Language en = WriterToolFactory.eINSTANCE.createLanguage(); en.setName("en"); Language de = WriterToolFactory.eINSTANCE.createLanguage(); en.setName("de"); Project project = WriterToolFactory.eINSTANCE.createProject(); project.getLanguages().add (en); project.getLanguages().add (de); project.setDefaultLanguage(en); // Verify the model works as expected assertEquals("List size is wrong", 2, project.getLanguages().size()); assertEquals("Order is wrong", "en", ((Language)project.getLanguages().get(0)).getName()); assertEquals("Order is wrong", "de", ((Language)project.getLanguages().get(1)).getName()); assertEquals("Default language is wrong", en, project.getDefaultLanguage()); assertEquals("Default language is wrong", "en", project.getDefaultLanguage().getName()); } } |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java (Line 1-32)
Let's run. We're green (as expected) but only one test as run.
It seems that Eclipse doesn't run every test in a project by default.
Go into Menu Run / Run ...
As expected, the BookTest runs just this single test. That's not what we want. Change the name of the run configuration to "WriterTool Tests" and select "Run all tests in the select project, package or source folder".
Run again.
Now, we have two tests but the second one fails. Grmpf.
Since the failed test run doesn't run away, we'll first share the launch config: Open the Run configuration dialog again and click on the Common tab. Here, you can find "Save as / Shared file:". Select "/WriterTool" and Run again.
The error didn't go away (it better didn't!) but in the Package Explorer, you have now a new file: "WriterTool Tests.launch". This file contains the settings to run the test. When the next person opens the project, he'll be all set up to run the tests without tedious searching.
Now back to the error. It seems that the sequence in the list is not as expected. Let's have a look at it:
22: | System.out.println(project.getLanguages()); |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java
The console now tells us that the name of the first item is "de" and null for the second one.
A quick glance at the test reveals why: When I wrote the test, I duplicated the creation of the english language but didn't change all the names. The code compiles but doesn't work as expected. Do you start to understand why I always test?
It's just two characters, a tiny typo but if I had no test, it would go productive without notice.
But also notice that we only caught this one because I actually checked the name attribute. I could also have checked if the elements were the objects. In this case, the error would have gone unnoticed. So the lesson here is to check what you really want to know (and not stop halfway) but that tests can give you a false sense of security.
A quick fix later, we're green.
I delete the System.out, because now, we know what's in the list (the failed test proved to us that it actually fails when something is wrong).
Before I start to use ENamedElement everywhere, I create the last-modification class/building block, because I'll want to add that at several places, too. This way, I can add both at once.
Create a new EClass "LastModification" with two attributes: creationTime and lastModification. Both are of type EDate.
Before we spread this change everywhere, we'll write some tests to see if it actually works as expected (so we don't have to undo everything later).
But where to add the new building block? If I added it to Book or Section, I would have to copy the setup code from BookTest. Author ... it seesm unlikely that I will want to have a modification time for authors. But it might be useful to know when something was changed in the project, so Project it is.
Open the ESuper Type dialog for Project and add ENamedElement and LastModification to it.
I wonder what kind of code EMF generates, now.
A lot of errors, it seems: Duplicate field WriterToolPackage.PROJECT__NAME in WriterToolPackage.java. Maybe I forgot to delete the field Project.name?
Sure thing. Once more.
Less errors this time but I still have PROJECT__NAME twice.
Both definitions look exactly the same, so I suspect that EMF can't decide which to drop. Maybe it just checks if there is such a field but not how often. To be sure, I delete both definitions and regenerate.
Ok, EMF generated the field again (one time). Another generate to make sure I don't have galloping field spread ... Nope, we're healty.
Did you notice that the file generation starts to take some time? Hm :-/
But first things first. We were on our way to look at name and lastModification in ProjectImpl.java (Project.java looks as you would expect; have a look yourself if you don't believe me).
It seems that EMF uses ENamedElementImpl as super class and generates the code to handle the last modification time and we have getters and setters.
This is not really what we want: The creation time should be set just once when the object is created, so the setter is dead wrong.
Just change Changeable to false (don't forget to save!) and regenerate.
Now, the setter for creation time is gone. But how to setup this field? Unfortunately, we have another problem: Initializing the field.
There are two problems here: We don't really want to have the setup code in every class which uses this building block. The name is probably much less problematic (at least right now), so we would like EMF to derive from LastModification and copy the name code into the ProjectImpl file.
And I wonder how EMF is going to set the field when it loads the project from a file. We want to know when a project was created for the first time, not when it was loaded from a file the last time.
We'll make a note about the load problem in the test case, so we won't forget about it.
And while we're at it, lastModification shouldn't change just because we load something from a file:
33: 34: | // FIXME Make sure Project.creationTime survives loading and saving // FIXME Make sure Project.lastModification survives loading and saving |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java (Line 33-34)
With our mind clear of these pending problems, we can concentrate on the real issue: How can I control inheritance?
Unfortunately, I cannot add code to the model. There is a Default Value Literal property but it's meant for constants which is a pity. A way to put "new Date()" in there would be cool.
I also cannot add code for the constructor in the model. All I could do was to add it manually to the Java files. And god forbid that I forget one place.
Tests would save me eventually, but I'm not taking the pains of Java's strong typing system for nothing. A mix-in? Static helper methods? Can EMFs notification framework give me a hint when a new object is created?
I could add some code to the factory but what I really want is a class (maybe an abstract one) which contains all this code in one place and tell EMF to generate the code for the name.
Let's see: EClasses have an abstract property. What happens when I set that to true?
According to the EMF book [FIXME link], it will delete the factory method (which is something I want: There is no reason to create single building blocks). A quick change and generate later, I have a look at the code.
Hm. It made LastModificationImpl abstract, deleted the factory method WriterToolFactory.createLastModification() but no change in ProjectImpl.
What now?
While browsing the dialogs and views, I notice that I can change the order of the super classes in the ESuper Type dialog. Out of curiosity, I move the LastModification class up.
Hey! Just what I wanted: ProjectImpl is now derived from LastModificationImpl and the name code is generated.
The next step is to set these fields. In the field declaration? In the constructor of LastModificationImpl?
Since I want to keep my changes out of EMFs way as much as possible, I chose the constructor. If I had changed the field declarations, that would have been two places where my code overrides EMFs code generation.
78: 79: 80: 81: 82: 83: 84: 85: 86: 87: | /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated NOT */ protected LastModificationImpl() { super(); creationTime = lastModification = new Date(); } |
/WriterTool/src/de.philmanndark.writertool.model.impl/LastModificationImpl.java (Line 78-87)
Note that I did two things: I added the NOT after @generated (line 81) and I inserted the line to setup the two fields (line 86).
Also note how easy it is to overlook this change. Only the string "NOT" tells you that EMF will now leave this method alone. One method out of ten. Just one line of 221. Anyone except me, who feels uneasy about this?
The problem here: Someone changes the model. He generates. Now, he expects that the new code behaves as he sees in the model. But it doesn't. And he has no way to see why.
The most natural solution would be to create another class which inherits from LastModificationImpl, put the code in there and then make ProjectImpl derive from our class (which contains all the manual changes).
But we're opening pandoras' box here: We would have to disable the code generation in a whole lot of places: The factory, the definition of the ProjectImpl class.
This shows some of the limits of code generation: No matter how clever a code generator is, you will eventually run into a situation where it gets in your way.
I had a length discussion about this with Ed Merks in the EMF newsgroup. He told me that one of the first versions of EMF would generate four classes instead of two.
Right now, we have an generated interface (GIface) and a generated implementation (GImpl). This version of EMF would also generate a user interface (UIface) and a user implementation (UImpl). These two files were initially (almost) empty.
The class tree looked like this: UIface extends GIface, GImpl implemnts UIface (like today), , UImpl extends GImpl.
Derived classes would derive from UImpl. "Been there, done that, threw it away", Ed said. "This resulted in significant code bloat and confusing class hierarchies, so this was dropped before EMF went open source."
So don't pester him about that, ok?
Back to testing.
Again, I have written code before the test. I call it flexibility.
So first we need a test to see if the new fields are correctly initialized. I'm not reusing the existing test because every test should cover only one feature. This way, changes to the model or the code shouldn't break many tests.
Just to be sure, I start the tests before I implement the next one. Nothing is more frustrating than running a new test and then finding that existing tests fail.
33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: 45: | /** * Create a project to check the date fields * * @throws Exception */ public void testCreate () throws Exception { Project project = WriterToolFactory.eINSTANCE.createProject(); assertNotNull("CreationTime is null", project.getCreationTime()); assertNotNull("LastModification is null", project.getLastModification()); assertEquals("Dates don't match", project.getCreationTime(), project.getLastModification()); } |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java (Line 33-45)
Save, run, we're green.
Next stop: last modification time.
Why do I initialize lastModification with creationTime? Wouldn't it make more sense to leave it as null? There was no change to the object, yet, right? Setting creationTime doesn't really count, does it?
Let's look at the usage: I will want to display the lastModification of many objects and if lastModification for unmodified objects was null, I would have to use this code:
1: | date = (lastModification == null) ? creationTime : lastModification |
As it is now, I can always use lastModification.
And I can still check if the object was modified by comparing creationTime with lastModification.
Plus one could argue that creating an object is a change to it.
So all in all, setting the field (especially since it's so cheap), is probably the better solution.
Remember the notification code when we had a first look at the generated code? This code is now going to save us a tremendous effort.
What we want is to be notified when any field of a class in out model changes, so we can update the last modification time. Of course, this should only happen for classes which have a last modification field and changes to the last modification field should not trigger these updates.
Also, loading an object from a file should not change the last modification field but we already have a FIXME for that. So first things first: A test which specifies the desired behavior:
49: 50: 51: 52: 53: 54: 55: 56: 57: 58: 59: 60: 61: 62: 63: 64: | /** * Make sure that changes to {@link Project.name} * update {@link LastModification.lastModification} * * @throws Exception */ public void testLastModification () throws Exception { Project project = WriterToolFactory.eINSTANCE.createProject(); Date before = project.getLastModification(); project.setName("dummy"); Date after = project.getLastModification(); if (after.equals(before)) fail ("lastModification didn't change"); } |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java (Line 49-64)
Let's run it. Isn't it nice when you get a failure when you expect one?
In EMF, the design pattern "adapter" is used to implement notification.
An adapter is a thing which adds functionality (adapts) to something else. Think of the tiny gadgets which allow you to plug your notebook into foreign power sockets.
Every EObject is derived from org.eclipse.emf.common.notify.Notifier. This interface defines two methods: eAdapters() and eNotify(). The latter will be called when an event happens (EMF takes care of that). All we have to do is to add our adapter to the list returned by eAdapters().
The notification code in EMF will, when eNotify() is called, walk through this list and call notifyChanged() on every element.
It would be very tedious (and error-prone) to have to add this adapter to every object which we create, even if we added this code to the factory. Fortunately, EMF already has a solution.
Remember the containment feature? EMF offers a special adapter which enhances objects which have fields with Containment == true: Whenever an object is added to such a field, the adapter will add itself to the object.
So all we have to do is to add the new adapter to Project objects. When we add books (contained/managed by project), the adapter will install itself in them. When sections are added, the adapter will already be in the book. If a book was added with existing sections, the adapter would install itself recursively.
So it's just one line of code:
1: | project.eAdapters().add(new LastModificationContentAdapter()); |
But where to put it? The factory seems a natural place since we want this adapter in every model, no matter who creates them and when (load, save, new or copying).
109: 110: 111: 112: 113: 114: 115: 116: 117: 118: 119: | /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated */ public Project createProject() { ProjectImpl project = new ProjectImpl(); project.eAdapters().add(new LastModificationContentAdapter()); return project; } |
/WriterTool/src/de.philmanndark.writertool.model.impl/WriterToolFactoryImpl.java (Line 109-119)
I just added line 117.
Did you notice something?
I forgot to add the NOT to @generated.
It's really easy to miss. Ok, here is how it should be:
109: 110: 111: 112: 113: 114: 115: 116: 117: 118: 119: | /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated NOT */ public Project createProject() { ProjectImpl project = new ProjectImpl(); project.eAdapters().add(new LastModificationContentAdapter()); return project; } |
/WriterTool/src/de.philmanndark.writertool.model.impl/WriterToolFactoryImpl.java (Line 109-119)
We will create the missing class LastModificationContentAdapter in de.philmanndark.writertool.model.util. Put org.eclipse.emf.ecore.util.EContentAdapter into the superclass field.
Afterwards, a simple Organize Imports in WriterToolFactoryImpl will fix the compile error.
Back to the content adapter. In notifyChanged, we'll have to do these things:
Here is a first attempt. I create the class in the util package to keep it out the way of EMFs code generator.
13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: 45: 46: 47: 48: 49: 50: 51: 52: 53: 54: 55: 56: 57: | public class LastModificationContentAdapter extends EContentAdapter { public void notifyChanged (Notification notification) { // Allow the EContentAdapter to do its own magic super.notifyChanged (notification); // Depending on the type of event ... switch (notification.getEventType ()) { case Notification.SET: // Did the attribute change at all? if (hasChanged (notification)) { // Make sure the object has the necessary fields if (notification.getNotifier() instanceof LastModification) { // Avoid recursive loops int featureID = notification.getFeatureID(LastModificationImpl.class); if (WriterToolPackage.LAST_MODIFICATION__LAST_MODIFICATION == featureID) return; ((EObject)notification.getNotifier()).eSet(WriterToolPackage.eINSTANCE.getLastModification_LastModification(), new Date()); } } break; case Notification.ADD: /* FIXME */throw new RuntimeException ("LMod: ADD "+notification.getNotifier ()+" "+notification.getNewValue ()); // FIXME break case Notification.REMOVE: /* FIXME */throw new RuntimeException ("LMod: REMOVE "+notification.getNotifier ()+" "+notification.getNewValue ()); // FIXME break; } } private boolean hasChanged (Notification notification) { if (notification.getOldValue () == null) return notification.getNewValue () != null; return !notification.getOldValue ().equals (notification.getNewValue ()); } } |
/WriterTool/src/de.philmanndark.writertool.model.util/LastModificationContentAdapter.java (Line 13-57)
60 lines in fact. Not really nothing but pretty cheap when it works as advertised. Note that I have added exception in all the places where I expect I will have to do some further work, so I really don't forget about it.
Notice the code in line 31: Instead of using reflection to check the existing fields (and handling N different exceptions), I ask EMF for the field which should be changed.
And in line 35, I'm using the reflection-like API of EMF to update lastModification. EMF handles all the dirty details (like casting, converting and error checking).
Let's run the tests.
Two failures ... hm. Okay, testLanguage() fails in ADD. Not much I can do right now. Let's see the other one.
This is a bit of disappointment: The failure in testLanguage tells me that the adapter is installed but why didn't the date change?
A little test to confirm a suspicion ... yes, I was right.
Here is what I did:
62: | if (after == before) |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java
Do you see it? I replaced equals() with ==.
"Oh no!" I hear you cry. "Never use == with objects!"
Here, we have to. Why? Because the resolution of Javas time service is limited to milliseconds. Milliseconds are next to nothing, you might say. But todays computers can do several million operations per second. In our case, setName() just doesn't take long enough for the time so change. Isn't it a pity that for once, out slow computer is too fast?
But we don't actually care if the date has really changed. We only care that someone replaced the Date with a new one (even if the time stored in it is the same). Therefore, for our case, the change is correct.
To make sure that no over-eager Java-OO-fanatic triggers this trap, we add a comment.
61: 62: 63: 64: 65: | Date after = project.getLastModification(); // equals() can return true here, because the time doesn't always change // Just check if a new object was created. if (after == before) fail ("lastModification didn't change"); |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java (Line 61-65)
In the Extreme Programming book, the authors say that every time, you feel the need for a comment, you have a bug in your code.
Why do we comment?
To explain something which isn't obvious from reading the code.
In other words: The code is too complex.
But comments aren't safe. Code is checked by the computer (compiler) and tests. A comment can say "Now, we create gold from lead". A comment can contain a text which was true two code revisions ago. A comment can be missing. Misleading. A blatant lie. Written by someone, who was on a completely wrong track at that time.
I think it's safe to say that every programmer in the world has already changed some code which had a comment and forgot to update the comment.
Therefore, I write only a few comments: If I'm absolutely sure that the code won't change or if I have to document some odd behaviour which I simply cannot express in code.
Why so many comments in the content adapter, then?
Because this code contains so many new and strange things that I felt unease. Actually, I wrote many comments before the code (kind of a pseudo-code) and then filled in the gaps.
Next time, when you see a comment, ask yourself: Is it really necessary? Why?
Back to the pending failure in testLanguage. When you add some new functionality and existing tests break, this is a sure sign that there are unexpected dependencies in your code.
This time, the failure is not as unexpected, though: We added something to all classes in the model (an adapter which spreads itself like a virus). So we have to tackle the next design issue: Is "adding language to project" a modification to project?
How about adding an author? Or a new book?
It's one of those times, when I really can't say. When I wrote the adapter code, I was pretty sure that adding and removing things in the lists should update the last modification time but now, I'm not so convinced anymore. I'm not sure about the opposite, either.
Thinking for some time about it, I decide that I don't have enough information right now to make an educated decision.
Therefore, I remove the exceptions and just leave the FIXMEs in there.
40: 41: 42: 43: 44: 45: 46: | case Notification.ADD: // FIXME ("LMod: ADD "+notification.getNotifier ()+" "+notification.getNewValue ()); break; case Notification.REMOVE: // FIXME ("LMod: REMOVE "+notification.getNotifier ()+" "+notification.getNewValue ()); break; |
/WriterTool/src/de.philmanndark.writertool.model.util/LastModificationContentAdapter.java (Line 40-46)
Green again.
When I can't fill in the code for a case but I know it will break when it is executed, I add an exception.
Unfortunately, Java doesn't allow to add a break after an exception. So later, when I fill in the code, I delete the exception, fill in the code, run.
And wonder why it doesn't work.
Of course, I forgot to replace the exception with a break, so the code falls through to the next case.
That's why I always add a "// FIXME break;" in the line below the exception.
Time to remove the duplication in our model. To make things more uniform, we'll replace "title" with "name", so we can reuse more code:
Errors in BookTest. Of course, getTitle() is no longer there. Two solutions: I could add these methods artificially to the interface (or use EMF's EOperation) and them implement these by simply calling get/setName().
Or I could replace these four calls in the test with get/setName(). Being the lazy type, I'll do the latter.
Tests ... I'm green.
But does it work? I copy the tests from Project to Book.
Wait ...
The adapter is added to the project, not the books. So adding a test to BookTest won't work. For testing purposes, I could connect the adapter manually to the books but I don't really care about testing the books. I want to see if the adapter really spreads itself. That would kill two birds with one stone.
Did you notice how brutal some proverbs are?
So our test again goes into ProjectTest. What I really wonder is what happens when I create the book and then, later, add it to the project.
Step one: Move the code to create a book in BookTest into a static method, so I can reuse it in the other test case.
Hmpf, refactoring doesn't work because I assign all the parts to different local variables. Ok, even if my heart bleeds, I have to copy the code.
52: 53: 54: 55: 56: 57: 58: 59: 60: 61: 62: 63: 64: 65: 66: 67: 68: 69: 70: 71: 72: 73: | public static Book createTestBook () { Book book = WriterToolFactory.eINSTANCE.createBook(); Section chapter1 = WriterToolFactory.eINSTANCE.createSection(); book.getChapters().add (chapter1); Section section = WriterToolFactory.eINSTANCE.createSection(); chapter1.getSubsections().add (section); Section chapter2 = WriterToolFactory.eINSTANCE.createSection(); book.getChapters().add (chapter2); chapter1.setName("Introduction"); chapter1.setText("This is chapter1."); section.setName("Section title"); section.setText("This is the section which is a child of chapter 1."); chapter2.setName("Bla Bla"); chapter2.setText("The second chapter."); return book; } |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java (Line 52-73)
Now the new test in ProjectTest:
68: 69: 70: 71: 72: 73: 74: 75: 76: 77: 78: 79: 80: 81: 82: 83: 84: 85: 86: 87: 88: 89: 90: 91: 92: 93: 94: 95: 96: 97: | public void testBookModificationBeforeAdd () throws Exception { Book book = BookTest.createTestBook(); Project project = WriterToolFactory.eINSTANCE.createProject(); Date before = project.getLastModification(); project.getBooks().add (book); if (before != project.getLastModification()) fail ("LMod of project changed while adding a book"); // I suspect that the lastMod adapter wasn't used, yet if (book.getLastModification() != book.getCreationTime()) fail ("LMod-adapter was active"); // Check that objects around the changed one are not affected Date b1 = book.getLastModification(); Date b2 = ((Section)book.getChapters().get(0)).getLastModification(); Date b3 = project.getLastModification(); book.setName("Xxx"); if (b1 == book.getLastModification()) fail ("LMod-adapter didn't fire"); if (b2 != ((Section)book.getChapters().get(0)).getLastModification()) fail ("LMod-adapter changed chapter"); if (b3 != project.getLastModification()) fail ("LMod-adapter changed project"); b1 = book.getLastModification(); book.setName(book.getName()); if (b1 != book.getLastModification()) fail ("LMod-adapter fired for non-change"); } |
/WriterTool/test/de.philmanndark.writertool.model/ProjectTest.java (Line 68-97)
A long one because the setup is so complicated.
72-75: Make sure the lastModification for the project doesn't change while adding book. Why? Well, currently, the code works this way. Chances are that I'll write code which depends on this (non-documented/undefined) behavior. With this test, I'll know when someone later changes this behavior.
77-79: My suspicion is that the adapter can't do anything when books with content are added to the project. How could it? It didn't knew about the objects before they were added to the project and therefore, he coudln't have managed the lastModification fields. But it's better to know than to suspect. Now, we know and the test will also tell us when this should change.
82-91: Another test: Modifications to the book should not spread to the project or the chapters in the book.
93-96: Lastly, I'm making sure that non-changes (setting a field with its old value) doesn't update lastModification.
Five tests and green.
If you look at the Problems View, you'll see a lot of warnings. Let's fix them: Select the project and then "Source / Organize Imports" from the context menu.
Two left: To fix the warning about the model/ folder, we can simply delete the line in build.properties.
But I don't want to add test/ to the exported sources of my plugin. I have no idea how to fix that. Anyone?
Time to think about the text model.