Welcome to part 3 of my WriterTool tutorial. If you followed the previous parts, you should find this project in your workspace.
If you didn't, then download the file and use "Import ..." from the File menu. Select "Existing Projects into Workspace" from the folder General.
Choose "Select archive file:" and enter the path to the downloaded file. Eclipse should now offer the project "WriterTool" in the big area in the middle. Click Finish to import it into your workspace.
If you want to have some fun with a group of software developers, just innocently ask what's the best text editor.
Hey, it's only text, right? How hard can it be?
You wouldn't believe.
There are people who can tell the author just from the text of a book. It seems that authors have certain way to write their texts. Patterns.
The same is true for software. When you are working in a team, over time, you'll be able to tell who wrote the code without using the annotate view.
It doesn't end there. There are people who write programs as easily in Lisp or Perl as I do in Java or Python.
I hate them. Disgusting. Bah.
The feeling is mutual. Perl developers despise the Java guys. Lispers look down on everyone else. Luckily, they are a dying species. Like the COBOLds. And don't get us started about Smalltalk.
My programming language is best.
The same applies to our text editors. Lisp guys just love Emacs. Java delopers love IntelliJ or Eclipse. That's an exclusive or. Some freaks still live in the Netbeans cave. Talk to a sys-admin and he'll frown about anything but VI (if you don't know, you don't want to).
When you're used to JEdit, the text editing mode of Eclipse really hurts.
Why?
Different editors have different strengths. Emacs saw light in 1975. It's a dinosaur with roughly 500 million different functions, macros and extensions. JEdit runs everywhere where Java runs (almost, as usual). Eclipse is very, very, very focused on Java. From a functional point of view, it's a very big Notepad.
And of course, the more one works with his/her editor, the more speedups he/she collects. Little gems, saving time. Keyboard shortcuts. Macros. It's a way of life. Sometimes.
And when you're really green with some editor, there is a huge price to be payed to switch to another. You no longer know the shortcuts. Complex keystrokes, moved into your spine years ago, suddenly wreak havoc on your work. You feel like a toad which someone glued to a highway: All around you, the other workers just zip by while you can't move an inch.
There is no such thing as the best text editor. I'm using JEdit, VI, nedit, Eclipse and Editplus. Most of the time. Each has its strenghts and weaknesses.
There will never be an agreement which is best. Never.
Text. ASCII or ISO-Latin-1? UTF-8? UTF-16? Any special kind of format? XML? HTML? SGML? RTF? A custom one? TeX? PostScript?
It doesn't help when we look at the user: Someone will want to type in the text for the various chapters of his or her book, press a button and would like to see a PDF or a nice web site.
Why not use some external program like Work or, if we want to stay OSS, Open Office?
Another design problem.
Most of the time, people will need only a very small fraction of all available functions of a work processor. Writing this text, I need only some markup for titles, paragraphs, the inserts and the code. Ok, there is the occasional output from the console. One or two exception stack traces. A couple of links.
It adds up. Let's make a list:
Maybe String wasn't the best of all choices for the text field in the Section class.
Open Office almost meets the bill. Unfortunately, it saves the document as an archive. Okay, we could take it apart but inside is a large string of characters without newlines. If I put that into Subversion or CVS, it cannot find the changes between the versions.
XML would be a good choice if there was a way to compress things a bit. When you have to type everything, you want a compact syntax and XML is not quite the same fun without editor support. Sorry, DocBook.
Looking at the editor issue, I have a bad feeling about this. I guess I will start with something which allows me to plug in a solution. An abstract Content class which defines the interface. Later, I can fill in some default solution and allow others, to extend it as they see fit.
Back to the ecore editor. Create a new EClass "Content". For now, it has just two fields: the language of the content and the content itself (String). Set the lower bound of the language to 1 (making it required) and Containment must be false.
Save and generate.
We'd like to support translations in the tool, so an author can concentrate in writing the texts in his own language. For every section of a book, the translators can add translations. The system should keep them together. I was thinking about going down to the paragraph level but that seems to be too fine-grained.
For now, I just want to be able to attach texts in different languages to a section.
Time to design the API. For this, I write a test with how I'd like to use the API. When I'm satisfied, I implement it. This test will go into BookTest.
75: 76: 77: 78: 79: 80: 81: 82: 83: 84: 85: 86: 87: 88: 89: 90: 91: 92: 93: 94: 95: 96: 97: 98: | public void testLangContent () throws Exception { Language en = WriterToolFactory.eINSTANCE.createLanguage(); en.setName("en"); Language de = WriterToolFactory.eINSTANCE.createLanguage(); de.setName("de"); Section chapter = WriterToolFactory.eINSTANCE.createSection(); chapter.setContent(en, "Summary", "The text of the chapter."); String deText = "Der Text des Kapitels.\n\n" + "Und weil es damit immer Ärger gibt: ein paar Umlaute: ÄÖÜäöüßÿ\n\n" + "Kanji: \u6021"; chapter.setText(de, deText); chapter.setSummary(de, "Zusammenfassung"); Content content = chapter.getContent (en); assertNotNull ("Content is null", content); assertEquals ("Summary(en) is wrong", "Summary", content.getSummary()); assertEquals ("Text(en) is wrong", "The text of the chapter.", content.getText()); assertEquals ("Summary(de) is wrong", "Summary", chapter.getSummary(de)); assertEquals ("Text(de) is wrong", deText, chapter.getText(de)); // FIXME Implement default language } |
While writing on the test, it orcurred to me that authors will probably want to be able to store short summaries for chapters, so I've added this to the API.
This gives three different APIs: One where I set everything at once and I expect the Section to create a new or update an existing Content object. Or I want to set just the text or summary. The last one is implicit (passing a Content object), so I've left that one out.
After adding the summary to the Content class, I wonder how I can map contents to languages. Smells like map. Another aproach would be through a list. But I like the map better. Let's see how EMF handles that.
After addint the Summary field, one of the errors is gone.
Time to try to add custom operations to the model.
In order to add the additional API to the model, I'm defining it with EOperations. EMF will turn that into additional methods in the interface and empty method bodies in the generated implementation.
For example, the EOperation setContent(Language,EString,EString) is implemented with this code:
220: 221: 222: 223: 224: 225: 226: 227: 228: 229: 230: | /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated */ public void setContent(Language language, String summary, String text) { // TODO: implement this method // Ensure that you remove @generated or mark it @generated NOT throw new UnsupportedOperationException(); } |
Instead of just creating an interface, EMF generates an (almost) empty method which calls an exception when it's used. This way, we won't forget about it.
Let's create the missing methods setText(), setSummary() and the getters.
Now, the test compiles but of course, it throws lots of exceptions when we run it.
Before I can really start to implement it, I must define the map.
Maps are a bit complicated in EMF. You can't simply use a java.util.Map. They probably had a very good reason for this, too, but I can't think of any.
Instead of a real map, EMF internally uses a list. The disadvantage is that EMap doesn't implement Map directly. On the pro side, the EMF Maps allow any kind of key (for example, an int and not only Objects) and you can store several values per key.
In case you need a real java.util.Map, you can call map() which will create an adapter for you that behaves like a real map.
Needless to say, everything is type-safe as with EMF ELists.
After this small detour, let's have a look at our model again. To use EMaps in my model, I need two things (just like with the Opposite feature): A definition of the map entries (must be derived from java.util.Map$Entry) and a reference which can contain any number of elements.
Especially the latter is tricky: If you set the Upper Bound to 1 (I want just one EMap in my class, right?), then EMF things that you want one entry of your map in the class. So to use EMaps, always set Lower Bound to 0 and Upper Bound to -1.
This allows us to create EMaps which contain a content object per language. The languages are only references (i.e. not managed by the map) but the values (the Content objects) are.
Now, we have something that looks strange but works as we want it. Let's look at the code.
The Section interface now contains an accessor for the map:
33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: 45: 46: 47: 48: | /** * Returns the value of the '<em><b>Content</b></em>' map. * The key is of type {@link de.philmanndark.writertool.model.Language}, * and the value is of type {@link de.philmanndark.writertool.model.Content}, * <!-- begin-user-doc --> * <p> * If the meaning of the '<em>Content</em>' map isn't clear, * there really should be more of a description here... * </p> * <!-- end-user-doc --> * @return the value of the '<em>Content</em>' map. * @see de.philmanndark.writertool.model.WriterToolPackage#getSection_Content() * @model mapType="de.philmanndark.writertool.model.ELanguageToContentMapEntry" keyType="de.philmanndark.writertool.model.Language" valueType="de.philmanndark.writertool.model.Content" * @generated */ EMap getContent(); |
Just what we want. Notice the additional items after the @model tag: EMF stores the types for the different objects in the Map.Entry there.
The field is very simple as well:
81: 82: 83: 84: 85: 86: 87: 88: 89: | /** * The cached value of the '{@link #getContent() <em>Content</em>}' map. * <!-- begin-user-doc --> * <!-- end-user-doc --> * @see #getContent() * @generated * @ordered */ protected EMap content = null; |
And the getter looks a lot like the code which we saw for EList:
162: 163: 164: 165: 166: 167: 168: 169: 170: 171: 172: 173: 174: 175: 176: 177: | /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated */ public EMap getContent() { if (content == null) { content = new EcoreEMap( WriterToolPackage.Literals.ELANGUAGE_TO_CONTENT_MAP_ENTRY, ELanguageToContentMapEntryImpl.class, this, WriterToolPackage.SECTION__CONTENT); } return content; } |
Since we can now store content in various languages to a section, we will want to model that class.
Did you notice that we just had to create the class (without any fields) to complete our model so far that we can compile the tests?
During the modeling phase, you will find yourself in this situation quite often. Try to concentrate on the current feature (the map) in this case, instead of trying to guess what you will need next (the values of the map).
As I wrote earlier, the text model not only be complicated but probably subject to religious wars. "XML! TeX! Word! OpenOffice! Text!", they'll yell.
Well, not at me. I plan to add an abstract Content to my model and ship with a couple of demo implementations so people can see how it works and how they can plug-in their own favorite editor.
Isn't it nice with Open Source Software that you can answer any implement-this-feature kind of attack with "Hey, you have the source, do it yourself!"?
So what should our content be able to do? Right now, I just want it to be able to store a summary of the content (possibly empty), so I just add a summary attribute.
Right now, I'm wondering if I'll need to know in which language the content is but since I can't answer this question and it's probably pretty simple to add it later, I postpone the decision.
When we generate the latest version of the model, many tests don't compile anymore. That's because I chose not to add a text attribute.
Here, we have another gap: When working with a code generator, then you'll find that it's view is limited. At some point, it's just out of its league.
In Eclipse, I'd just refactor the code. When I change something in my model and regenerate, a lot of bad things can happen.
I'll return to this in a bit.
Right now, the fix is pretty easy: I just have to add a StringContent class which has a text field. It's simple, because I just add to the model. Changing and removing causes the pain.
Now, we have a lot of errors in BookTest. Which makes sense since our model has changed quite a bit. This is the reason why test code should be as simple as possible: You should never have to feel sad when you delete a test case.
createTestBook() is a different matter: This is code which we'll want to reuse. But to create a simple book, we need languages which are part of the project. Tight coupling is to be avoided but languages are more like constants, so maybe it's not so bad in our case.
This looks as if we have to move the code from BookTest to ProjectTest.
In ProjectTest, I create a new factory which creates a sample project with a couple of languages. Then, I use this empty project to create my test books.
Looking into ProjectTest, I see that testLanguage already contains most of the code I need. After a bit of refactoring, I come up with this:
93: 94: 95: 96: 97: 98: 99: 100: 101: 102: 103: 104: 105: 106: 107: 108: 109: 110: 111: 112: 113: 114: 115: 116: 117: 118: 119: 120: 121: 122: 123: 124: 125: 126: 127: | private static Language EN; private static Language DE; public static Project createTestProject() { Language en = EN(); Language de = DE(); Project project = WriterToolFactory.eINSTANCE.createProject(); project.getLanguages().add (en); project.getLanguages().add (de); project.setDefaultLanguage(en); return project; } public static Language EN() { if (EN == null) { EN = WriterToolFactory.eINSTANCE.createLanguage(); EN.setName("en"); } return EN; } public static Language DE() { if (DE == null) { DE = WriterToolFactory.eINSTANCE.createLanguage(); DE.setName("de"); } return DE; } |
I put such helpers at the end of my test classes so I don't have to scroll past them every time I open the file in an editor.
testLanguage() has now become a bit shorter:
21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: | public void testLanguage () throws Exception { Project project = createTestProject(); // Verify the model works as expected assertEquals("List size is wrong", 2, project.getLanguages().size()); assertEquals("Order is wrong", "en", ((Language)project.getLanguages().get(0)).getName()); assertEquals("Order is wrong", "de", ((Language)project.getLanguages().get(1)).getName()); assertEquals("Default language is wrong", EN(), project.getDefaultLanguage()); assertEquals("Default language is wrong", "en", project.getDefaultLanguage().getName()); } |
I'd love to run my tests right now (like many TDD developers, I get itchy when I can't test for more than one hour) but all those error messages scare me.
I wish I hadn't deleted testCreate(), I realize now. With just a few changes (replacing setText() with setSummary(), I could have fixed many of the errors. No problem, though: Context Menu, Replace With, Local History ..., a bit of browsing and my code is back.
Did you ever notice how many useful functions Eclipse has and how much more productive you are with it? Amazing. :-)
Since I need a lot of sample chapters, I add a couple of factory methods to help me build my models:
89: 90: 91: 92: 93: 94: 95: 96: 97: 98: 99: 100: 101: 102: 103: 104: 105: | public static Section createSection(Language lang, String name, String summary, String text) { Section s = WriterToolFactory.eINSTANCE.createSection(); s.setName(name); addStringContent(s, lang, summary, text); return s; } public static void addStringContent(Section s, Language lang, String summary, String text) { StringContent sc = WriterToolFactory.eINSTANCE.createStringContent(); s.setContent(lang, sc); sc.setSummary(summary); sc.setText(text); } |
These make the tests even shorter which is always a good thing.
7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: 45: 46: 47: 48: 49: 50: 51: 52: 53: 54: 55: 56: 57: 58: 59: 60: 61: 62: 63: 64: 65: 66: 67: 68: 69: 70: 71: 72: 73: 74: 75: 76: 77: 78: 79: 80: 81: 82: 83: 84: 85: 86: 87: | /** * Create a book with two chapters and one section. * * @throws Exception */ public void testCreate () throws Exception { Language en = ProjectTest.EN(); // Use the factory to create a book Book book = WriterToolFactory.eINSTANCE.createBook(); // Create a chapter and add it to the book Section chapter1 = createSection (en, "Introduction", "This is the summary of chapter1.", "This is the text of chapter1."); book.getChapters().add (chapter1); // Create a section and add it to the first chapter Section section = createSection(en, "Section title", "This is the section which is a child of chapter 1.", null); chapter1.getSubsections().add (section); // And another chapter Section chapter2 = createSection(en, "Bla Bla", "The second chapter.", null); book.getChapters().add (chapter2); // Check some relations assertTrue("Chapter 1 is not contained in the book", book.getChapters().contains(chapter1)); assertTrue("Chapter 2 is not contained in the book", book.getChapters().contains(chapter2)); assertFalse("The section is contained in the book", book.getChapters().contains(section)); assertTrue("The section is not contained in chapter 1", chapter1.getSubsections().contains(section)); assertTrue("Chapter 2 contains sections", chapter2.getSubsections().isEmpty()); assertEquals("The number of chapters in the book is wrong", 2, book.getChapters().size()); assertEquals("Title of chapter 1 is wrong", "Introduction", chapter1.getName()); assertEquals("Summary of chapter 1 is wrong", "This is the summary of chapter1.", chapter1.getSummary(en)); StringContent sc = (StringContent)chapter1.getContent(en); assertNotNull("Couldn't get content", sc); assertEquals("Text of chapter 1 is wrong", "This is the text of chapter1.", sc.getText()); assertEquals("Title of the section is wrong", "Section title", section.getName()); assertEquals("Summary of the section is wrong", "This is the section which is a child of chapter 1.", section.getSummary(en)); assertEquals("Title of chapter 2 is wrong", "Bla Bla", chapter2.getName()); assertEquals("Summary of chapter 2 is wrong", "The second chapter.", chapter2.getSummary(en)); } public void testLangContent () throws Exception { Language en = ProjectTest.EN(); Language de = ProjectTest.DE(); String deText = "Der Text des Kapitels.\n\n" + "Und weil es damit immer Ärger gibt: ein paar Umlaute: öäüÖÄÜ\n\n" + "Kanji: \u6021"; Section chapter = createSection(en, null, "Summary", "The text of the chapter."); addStringContent(chapter, de, "Zusammenfassung", deText); Content content = chapter.getContent (en); assertNotNull ("Content is null", content); assertEquals ("Summary(en) is wrong", "Summary", content.getSummary()); assertEquals ("Text(en) is wrong", "The text of the chapter.", ((StringContent)content).getText()); assertEquals ("Summary(de) is wrong", "Zusammenfassung", chapter.getSummary(de)); assertEquals ("Text(de) is wrong", deText, ((StringContent)chapter.getContent(de)).getText()); // FIXME Implement default language } public static Book createTestBook () { Language en = ProjectTest.EN(); Book book = WriterToolFactory.eINSTANCE.createBook(); Section chapter1 = createSection(en, "Introduction", "This is chapter1.", null); book.getChapters().add (chapter1); Section section = createSection(en, "Section title", "This is the section which is a child of chapter 1.", null); chapter1.getSubsections().add (section); Section chapter2 = createSection(en, "Bla Bla", "The second chapter.", null); book.getChapters().add (chapter2); return book; } |
Run ... we're green.
If you're not green, you might see some strange characters after the message "Text(de) is wrong". In this case, you have an encoding or charset problem.
If this is the case, then go into the Edit menu / Set Encoding. Select Other: UTF-8. The strange characters in the source should now be fixed. If not, cut&paste them again.
If you live outside of America and England, you will be used to some strange characters in your language: Umlauts.
For a computer, it's just a binary pattern. In XML, there is a field encoding in the header of the file which says which encoding was used when the document was created.
Java has no such thing. This is even more strange since you can use any valid Unicode letter in Java identifiers:
1: 2: | int rübezahl = 5; String 兎 = "Usagi"; |
Use cut&paste if you don't believe me.
In order to fix the problem, Eclipse allows to specify the encoding on a per-file basis.
Since we now have an abstract Content object, let's ponder where else it might be useful. How about book?
A book doesn't only contain chapters and a title but also several texts: On the back cover and inside the flap. I'm not really sure how useful that is, but adding these is just a cut&paste away: I simply copy the content reference from Section to book (twice) and change the names (backCoverContent and insideFlapContent).
Or it would be if there were a way to copy the implementations of the EOperations as well (copying the definitions is simple).
Authors could use content, too: Notices, telephone number, a short description, preferred language of contact.
Ideas, places, characters will need descriptions.
It looks like we'll use the content in various places.
Again, we face the polymorphic problem: We have code in LastModification which is needed everywhere and we now have another class which needs the same.
Looking closer at the problem, I find it hard to come up with a case where I would need only one of the two. If an object has content, I also want to track its modification time.
So the solution is to create another base class (like LastModification) which derived from LastModification and implements the Content functions. I'll call this class ContentProvider.
It compiles and the tests are green. An excellent basis for the next step.
Just like with the default language, you will have a preferred content type. For my tests, I use StringContent, so I would like that the factory method in WriterToolFactory returns those by default.
But when someone else uses the application, she'll want a simple way to plug in his own implementation so she can use her favorite editor.
Since all accesses happen view eINSTANCE in the interface WriterToolPackage, the most simple solution would be to replace this constant. Unfortunately, constants in interfaces are final in Java, so we can't do that.
So the next best solution is to create an interface which returns content objects of the desired type and to add that to WriterToolPackageImpl.
Since everyone uses WriterToolFactory.eINSTANCE to access the factory, the most simple way to inject your own classes into the model would be to change this field.
Unfortunately, this field is in a Java interface which means it's off limits: After Java has loaded the class, there is no way to change it.
Basically, it's impossible to extend an existing EMF model. It is set into stone, even when it looks as if you could extend it.
There is an important lesson here: Small design decisions which make sense while you make it can have very bad side effects on other people.
Which is why creating good frameworks is so very hard. You can never know for what someone else will use your code.
160: 161: 162: 163: 164: 165: 166: 167: 168: 169: 170: 171: 172: 173: 174: 175: 176: | public static interface ContentFactory { Content createContent(); } public static ContentFactory CONTENT_FACTORY; /** * <!-- begin-user-doc --> * <!-- end-user-doc --> * @generated NOT */ public Content createContent() { // If you get a NPE here, you must initialize CONTENT_FACTORY return CONTENT_FACTORY.createContent(); } |
Why don't I initialize the factory?
Because I have no default which will work for most people. And a crash will help someone new to my code to find the documentation. The documentation is a bit, uh, terse, right now, but when I start adding more implementations, I'll add a more useful one.
Let's try the new factory. First, we run the tests. They are still green, because I use the correct factory everywhere. Let's change that.
101: | StringContent sc = (StringContent) WriterToolFactory.eINSTANCE.createContent(); |
Now, the tests are red as they should be. Time to create a setUp() method:
109: 110: 111: 112: 113: 114: 115: 116: 117: 118: 119: 120: 121: | protected void setUp() throws Exception { super.setUp(); WriterToolFactoryImpl.CONTENT_FACTORY = new ContentFactory () { public Content createContent() { return WriterToolFactory.eINSTANCE.createStringContent(); } }; } |
And green again.
Just to be sure, I'll let Eclipse search for all uses of createStringContent() and createConten() (References / Workspace in the context menu or Ctrl-Shift-G).
There is one in WriterToolFactoryImpl and one in BookTest.setUp(). The former doesn't look suspicious, so I can leave it alone. The search for createContent() returns similar results.
Since I feel that my model contains now all the necessary building blocks, I go wide: I start to use the building blocks to create more classes use the existing ones and don't add any special new features.
Let's start with Idea, Character, Place and Event.
Later in the project, authors will start with a collection of ideas. They will want to give them a certain order and create relations between them (for navigation and context building).
With the ideas will come the main characters in the story.
The places where the events happen.
The events themselves.
What's the differenence between an event and an idea? Events make up a kind of timeline (what happens when) while the ideas are more remote to the story. They contain the ideas for the key events or unused stuff. Events will be used to model the story from the ideas.
That means we need to be able to create close relations between these objects: Ideas will have lists of characters, places and events mentioned in them. Events will have a list of ideas used in them, characters to which the event happened. Places will be visited.
Characters have relations between each other: Friend, enemy of, wife, husband, ally, traitor, member of a specific race, caste or religion.
While we should not force an author to use all these, it would be nice to be able to. So here we have a list for the Events:
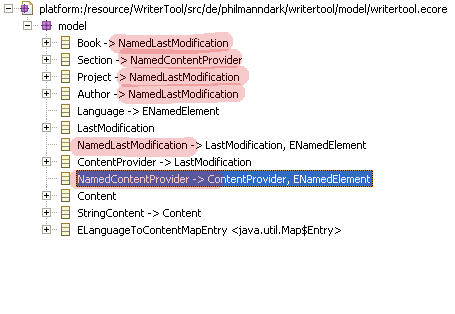
While creating the Event class, I notice that all my ContentProviders also derive from ENamedElement. Actually, everything derived from LastModification also includes ENamedElement, except for ContentProvider.
I'm tempted to derive LastModification from ENamedElement but then, I'd loose a bit of freedom. Instead, I create NamedLastModification and let it derive from LastModification and ENamedElement. This way, I now have three buildung blocks and thus, more flexibility. And since ContentProviders always have a name, I also create NamedContentProvider.
These classes have no fields but they just collect the most often used building blocks. The model now looks like this:
Save and generate.
I now have a lot of warnings about unused imports but no errors. I run Organize Imports and then my tests.
I'm green.
As we have seen with our problems to inject a Content-factory method, code generators always get in your way. This is because we have two goals which negate each other: We want it simple and powerful.
The most simple way to talk to a Java compiler is Java.
As soon as you move away from Java, you're giving up the fine grained control you have with the language itself.
But you get something in return: Control over far reaching aspects.
Our simple model now has 28 model classes and 7 helper classes.
Still, we were able to change the class tree (which class derived from which) within a few moments.
We can't control anymore what goes on at the Java level but now, we have much better control at the model level.
Since events refer to ideas, characters, places and sections, I have to add these other classes to be able to create the references between them.
In this example, I'm tempted to create a Character class which is different from java.lang.Character but has the same class name.
It's even more tempting because "Character" is the correct name ("main characters", "the characters in my book/story") and because I usually won't have to use both in the same file.
Or so I think. Or hope.
Because renaming a class is cheap in EMF but expensive in the rest of the code.
Usually, I prefer to avoid such names. Even "Content" is a bit generic for my taste and might lead to unhappy name collisions later.
The model should now look like this:
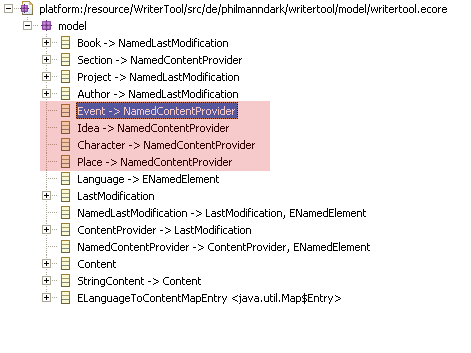
Since I have the classes, I can create the references (0..*, no containment).
To Event, I add references to ideas, characters and places.
I copy characters and places to Idea. I need no reference back to Event because when I want to find all events which are related to an idea, I can search the ideas list in Event.
Characters just need a reference to places to which they are related (place of birth, for example). To get all ideas which mention a character, I can search the ideas.
Places doesn't need anything anymore.
Time to take a step back and think a bit about this model.
We see that Idea and Event contain many references while Place has none. Would it make sense to even this out? Should I create back references?
Let's look at the usage.
An author will start with a couple of ideas. There will be a couple of them.
As soon as the project really kicks off, he'll start to sort his ideas in events to create a backbone of the story.
There will probably be more events than ideas. So every unused field in Event needs more space than when it was in Idea. The other side of the medal is search time. When I usually start my navigation from Event, I won't need to search at all: The lists already contain the information I want. When I start from Idea, I'll have to search all lists in all Events.
Scary thought.
I really can't say right now what the usage pattern will be. An author which never uses this navigation won't notice any performance problems but a high memory usage. Another author might use the model in a quite unexpected way and will curse for the slow search performance.
On the other hand, I can create proxy lists which contain the missing information later while I load the model from a data source. Or when the author actually navigates such a list for the first time. This is how Eclipse works: It knows about all its plug-ins but it only loads them when you use them for the first time.
That will make the experience sluggish once.
Since I don't have enough information right now, I have to postpone the decision once more.
I also have to add references to Section. Again do I add them to Section or to the other side?
I decide to add the reference to the other side (Event, Idea, Character and Place). There is no really good reason for this decision other than I have to put it somewhere.
There needs to be a manager for the new objects, so I add containment references to Project. The most simply way is to copy books and change the Name and EType.
While I did that, I thought that I like to sort my ideas hierarchical (in a tree). To be able to do that, I can simply copy the containment reference Project.ideas to Idea.
Within a few minutes, our model has grown substantially. Let's go back to testing.
After saving and generating.
Most of the new classes belong to the project (their manager), so the most natural place for the tests is ProjectTest.
First, I'll copy the setup code from BookTest.
Did I say copy? Never copy code!
Of course, I move the code into a static helper methode and call it from both places.
132: 133: 134: 135: 136: 137: 138: 139: 140: 141: 142: 143: 144: 145: 146: 147: 148: | protected void setUp() throws Exception { super.setUp(); ProjectTest.registerStringContentFactory(); } public static void registerStringContentFactory() { WriterToolFactoryImpl.CONTENT_FACTORY = new ContentFactory () { public Content createContent() { return WriterToolFactory.eINSTANCE.createStringContent(); } }; } |
The next step is to add help methods to create various kinds of initialized objects. Let's start with Idea:
112: 113: 114: 115: 116: 117: 118: | public static Idea addIdea (Project project, String name, String summary, String content) { Idea idea = WriterToolFactory.eINSTANCE.createIdea(); idea.setName(name); idea.setSummary(language, summary); return idea; } |
Imagine my cursor hovering in line 116. An idea in different languages? That doesn't make sense.
Since I want my code to compile, I'll use project.getDefaultLanguage() but a nagging feeling that there is something broken remains.
So the final code looks like this:
112: 113: 114: 115: 116: 117: 118: 119: 120: 121: 122: 123: 124: 125: 126: 127: 128: 129: 130: 131: | public static Idea addIdea (Project project, String name, String summary, String text) { Idea idea = WriterToolFactory.eINSTANCE.createIdea(); init (idea, project.getDefaultLanguage(), name, summary, text); return idea; } public static void init(NamedContentProvider ncp, Language lang, String name, String summary, String text) { ncp.setName(name); setContent (ncp, lang, name, summary, text); } public static void setContent (NamedContentProvider ncp, Language lang, String name, String summary, String text) { StringContent c = (StringContent)ncp.getOrCreateContent(lang); ncp.setContent(lang, c); c.setSummary(summary); c.setText(text); } |
The final version is now split into three different methods so I can reuse the setup code for Event, Character and Place.
Let's create a relatively big test project. While writing the code, I noticed that Author has content, too, so I changed the ESuper Type to NamedContentProvider.
And I'd like to be able to next events, to I added a containment reference just like the one in Idea.
92: 93: 94: 95: 96: 97: 98: 99: 100: 101: 102: 103: 104: 105: 106: 107: 108: 109: 110: 111: 112: 113: 114: 115: 116: 117: 118: 119: 120: 121: | public void testBigProject () throws Exception { Project project = createBigTestProject (); // Just some checks assertEquals ("Author count is wrong", 1, project.getAuthors().size()); } // FIXME Make sure Project.creationTime survives loading and saving // FIXME Make sure Project.lastModification survives loading and saving private static Language EN; private static Language DE; public static Project createBigTestProject () { Project project = createTestProject (); Book book = BookTest.createTestBook(); project.getBooks().add (book); addAuthor(project, "Aaron Digulla", "The guy behind this project", "Living in Switzerland\n\nSoftware developer"); addIdea(project, "Keywords", "It would be cool to be able to add keywords to objects", "Keywords might make navigation in large projects easier (see Flickr.com)"); addEvent(project, "Project start", null, null); Event e = addEvent(project, "Started doc project", null, "Started a second project which contains the diary of the creation of this one."); addEvent (e, project.getDefaultLanguage(), "Added jedit.jar", null, "This allows me to use the syntax highlighting code.\n\n" + "Now, I can cut&paste the Java source directly into the XML files."); return project; } |
Running the tests showed that I was sloppy once more: Maybe I should actually add the children to project after creating them (line 141 added).
137: 138: 139: 140: 141: 142: 143: | public static Author addAuthor (Project project, String name, String summary, String text) { Author author = WriterToolFactory.eINSTANCE.createAuthor(); init (author, project.getDefaultLanguage(), name, summary, text); project.getAuthors().add(author); return author; } |
This more or less concludes the model. We'll still change it many times but that's basically the set of all operations we'll need.
The next step is to save our model in a file. This is discussed in the chapter about persistence.